구문 분석 트리로 문법적으로 뿌리를 내리기
원문 : Grammatically Rooting Oneself With Parse Trees - Vaidehi Joshi
기술의 세계에서 우리를 둘러싼 모든 추상적인 개념에 대해 생각하는 것은 때때로 압도적일 수 있습니다. 특히 새로운 패러다임을 이해하려고 하거나 이해하기 어려운 하나 또는 여러 개념의 레이어를 풀려고 할 때 더욱 그렇습니다.
컴퓨터 과학을 배우는 맥락에서는 추상적인 개념이 너무 많아서 이를 모두 알고, 보고, 인식하는 것은 말할 것도 없고 이해하기도 어렵습니다!
추상화는 그 너머를 볼 수 있을 때 강력한 힘을 발휘하며, 어떤 것이 어떻게 추상화되고 왜 추상화되었는지 이해할 수 있다면 더 나은 프로그래머가 될 수 있습니다. 하지만 동시에 모든 추상화는 우리가 일상에서 추상화에 대해 걱정할 필요가 없도록 하기 위해 만들어진 것이기도 합니다! 우리가 항상 추상화에 대해 생각해야 하는 것은 아니며, 대부분의 경우 실제로 추상화를 생각하는 사람은 거의 없습니다. 하지만 중요한 것은 어떤 추상화는 다른 추상화보다 더 동등하다는 것입니다. 대부분의 엔지니어가 관심을 갖는 추상화는 컴퓨터와 소통하는 방식과 컴퓨터가 실제로 이해하는 방식과 관련된 것일 것입니다. 버블 정렬 알고리즘을 작성할 필요가 없더라도 코드를 작성한다면 기계와 소통해야 합니다.
이제 드디어 이러한 수수께끼를 풀고 프로그래머로서 우리의 워크플로우를 뒷받침하는 추상화를 이해할 때가 되었습니다.
구문 분석의 의미 파악하기
트리 데이터 구조는 컴퓨터 과학의 모험에서 계속 반복해서 등장하는 데이터 구조입니다. 모든 유형의 데이터를 저장하는 데 사용되는 것을 보았고, 자체적으로 균형을 잡는 트리도 보았으며, 공간과 스토리지 처리를 위해 최적화된 트리도 보았습니다. 심지어 트리를 회전하고 색을 바꿔서 일련의 규칙에 맞도록 조작하는 방법도 살펴봤습니다.
하지만 이러한 다양한 형태의 데이터 구조에도 불구하고 우리가 아직 발견하지 못한 트리 데이터 구조의 특별한 반복이 하나 있습니다. 컴퓨터 과학이나 트리의 균형을 맞추는 방법, 트리 데이터 구조가 어떻게 작동하는지 전혀 모르더라도 코드를 작성하는 모든 개발자는 자신의 코드를 기계가 이해할 수 있도록 해야 한다는 단순한 사실 때문에 모든 프로그래머는 매일 한 가지 유형의 트리 구조와 상호작용합니다.
이 데이터 구조를 구문 분석 트리(parse tree)라고 하며, 프로그래머가 작성한 코드를 컴퓨터가 ‘읽을 수 있게’ 해주는 기본 추상화 중 하나입니다.

구문 분석 트리의 핵심은 문장의 문법 구조를 그림으로 표현한 것입니다. 구문 분석 트리는 사실 언어학 분야에 뿌리를 두고 있지만, 교육학에서도 사용됩니다. 구문 분석 트리는 학생들에게 문장의 각 부분을 식별하는 방법을 가르치는 데 자주 사용되며, 문법 개념을 소개하는 일반적인 방법입니다. 우리 중 일부는 초등학교 때 배웠던 문장 다이어그램화의 관점에서 구문 분석 트리를 접해본 적이 있을 것입니다.
구문 분석 트리는 문장의 ‘도식화된’ 형태일 뿐이며, 어떤 언어로든 문장을 작성할 수 있으므로 어떤 문법 규칙도 준수할 수 있습니다.
문장 다이어그램화는 하나의 문장을 가장 작고 뚜렷한 부분으로 나누는 작업을 포함합니다. 문장을 다이어그램화한다는 관점에서 구문 분석 트리를 생각해 보면 문장의 문법과 언어에 따라 구문 분석 트리가 정말 다양한 방식으로 구성될 수 있다는 사실을 금방 깨닫게 될 것입니다!
하지만 컴퓨터 버전의 ‘문장’이란 정확히 무엇일까요? 그리고 정확히 어떻게 다이어그램화할 수 있을까요?
우리가 이미 익숙한 것의 예로 시작하는 것이 도움이 되므로 일반적인 영어 문장을 도표화하여 기억을 되살려 봅시다.
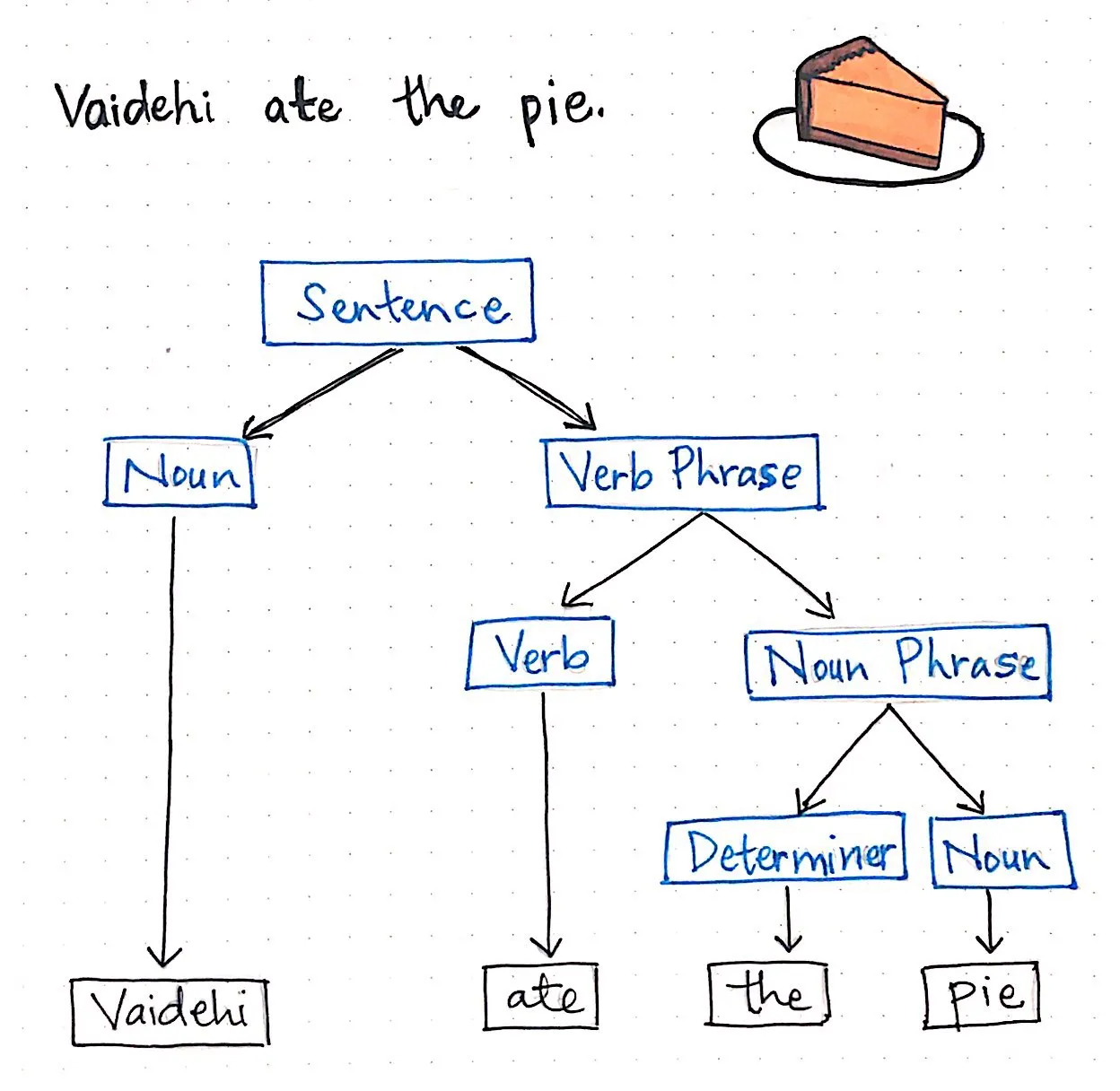
여기에 표시된 그림에는 간단한 문장이 있습니다: "Vaidehi ate the pie". 구문 분석 트리는 다이어그램화된 문장이라는 것을 알고 있으므로 이 예제 문장에서 구문 분석 트리를 만들 수 있습니다. 우리가 하려는 일은 이 문장의 여러 부분을 파악하여 가장 작고 뚜렷한 부분으로 나누는 것뿐이라는 점을 기억하세요.
먼저 문장을 명사 'Vaidehi'와 동사구 'ate the pie'의 두 부분으로 나눌 수 있습니다. 명사는 더 이상 세분화할 수 없으므로 "Vaidehi"라는 단어는 그대로 두겠습니다. 또 다른 방법으로 생각할 수 있는 것은 명사를 더 이상 세분화할 수 없기 때문에 이 단어에서 나오는 하위 노드가 없다는 사실입니다.
하지만 동사 구문인 "ate the pie"는 어떨까요? 이 구문은 아직 가장 단순한 형태로 분해되지 않았죠? 더 자세히 분석해 볼 수 있습니다. 우선, "ate"라는 단어는 동사이고 "the pie"은 명사에 가깝지만, 사실 완전히 구체적으로 말하면 명사 구문입니다. "ate the pie"를 분리하면 동사와 명사 구문으로 나눌 수 있습니다. 동사는 추가 세부 사항으로 다이어그램화할 수 없으므로 "ate"라는 단어는 구문 분석 트리에서 리프 노드(leaf node)가 됩니다.
이제 남은 것은 명사 구문인 “the pie”입니다. 이 구문을 명사 ‘pie’와 명사의 수식어라고 하는 결정자(결정자)의 두 가지 조각으로 나눌 수 있습니다. 이 경우 결정자는 “the”라는 단어입니다.
명사구를 나누면 문장 분할이 끝났습니다! 다시 말해, 구문 분석 트리 다이어그램을 완성한 것입니다. 구문 분석 트리를 보면 문장이 여전히 같은 방식으로 읽히며 실제로는 전혀 수정하지 않았음을 알 수 있습니다. 우리는 주어진 문장을 가지고 영어 문법의 규칙을 사용하여 가장 작고 뚜렷한 부분으로 나눈 것뿐입니다.
영어의 경우 모든 문장의 가장 작은 ‘부분’은 단어이며, 단어는 명사구 또는 동사구와 같은 구문으로 결합될 수 있고, 이 구문은 다시 다른 구문과 결합되어 문장 표현을 만들 수 있습니다.

그러나 이것은 특정 언어의 특정 문장을 고유한 문법 규칙으로 구문 분석 트리로 도식화하는 방법의 한 예일 뿐입니다. 같은 문장이 다른 언어에서는 매우 다르게 보일 것입니다. 특히 자체적인 문법 규칙을 따라야 하는 경우에는 더욱 그렇습니다.
궁극적으로 한 언어의 문법(grammer)과 구문(syntax)(해당 언어의 문장 구조 방식 포함)은 그 언어가 정의되는 방식, 우리가 그 언어로 글을 쓰는 방식, 그리고 그 언어를 사용하는 사람들이 그 언어를 이해하고 해석하는 방식을 규정하는 규칙이 됩니다.
흥미롭게도 우리는 이미 영어 문법에 익숙했기 때문에 “Vaidehi ate the pie.”라는 간단한 문장을 도식화하는 방법을 알고 있었습니다. 만약 이 문장에 명사나 동사가 하나라도 빠진다고 상상해 보세요. 어떻게 될까요? 아마 처음 문장을 읽었을 때 문장이 전혀 문장이 아니라는 것을 금방 알아차릴 것입니다! 오히려 문장을 읽으면 거의 즉시 문장 조각이나 불완전한 문장을 다루고 있다는 것을 알 수 있을 것입니다.
그러나 우리가 문장 조각을 인식할 수 있는 유일한 이유는 영어의 규칙, 즉 (거의) 모든 문장이 유효한 것으로 간주되려면 명사와 동사가 필요하다는 규칙을 알고 있기 때문입니다. 언어의 문법은 해당 언어에서 문장이 유효한지 확인하는 방법이며, 이러한 유효성 ‘확인’ 과정을 문장 파싱(Parsing)이라고 합니다.
문장을 처음 읽을 때 문장을 이해하기 위해 구문 분석하는 과정은 문장을 도표화하는 것과 동일한 정신적 단계를 포함하며, 문장을 도표화하는 것은 구문 분석 트리를 구축하는 것과 동일한 단계를 포함합니다. 우리가 처음으로 문장을 읽을 때 우리는 문장을 정신적으로 해체하고 구문 분석하는 작업을 하고 있는 것입니다.
알고 보면 컴퓨터도 우리가 작성하는 코드와 똑같은 작업을 수행합니다!
우리 일처럼 표현식 구문 분석하기
이제 영어 문장을 다이어그램화하고 구문 분석하는 방법을 알았습니다. 하지만 코드에는 어떻게 적용할 수 있을까요? 그리고 코드에서 ‘문장’이란 도대체 무엇일까요?
구문 분석 트리는 코드가 어떻게 보이는지 설명한 ‘그림’이라고 생각할 수 있습니다. 코드, 프로그램, 심지어 가장 단순한 스크립트를 문장 형태로 상상해 보면 우리가 작성하는 모든 코드가 표현식 집합으로 단순화될 수 있다는 사실을 금방 깨닫게 될 것입니다.
예를 들어 아주 간단한 계산기 프로그램을 살펴보겠습니다. 단일 표현식을 사용하면 수학의 문법적 ‘규칙’을 사용하여 해당 표현식에서 구문 분석 트리를 만들 수 있습니다. 표현식에서 가장 단순하고 뚜렷한 단위를 찾아야 하므로 아래 그림과 같이 표현식을 더 작은 부분으로 쪼개야 합니다.
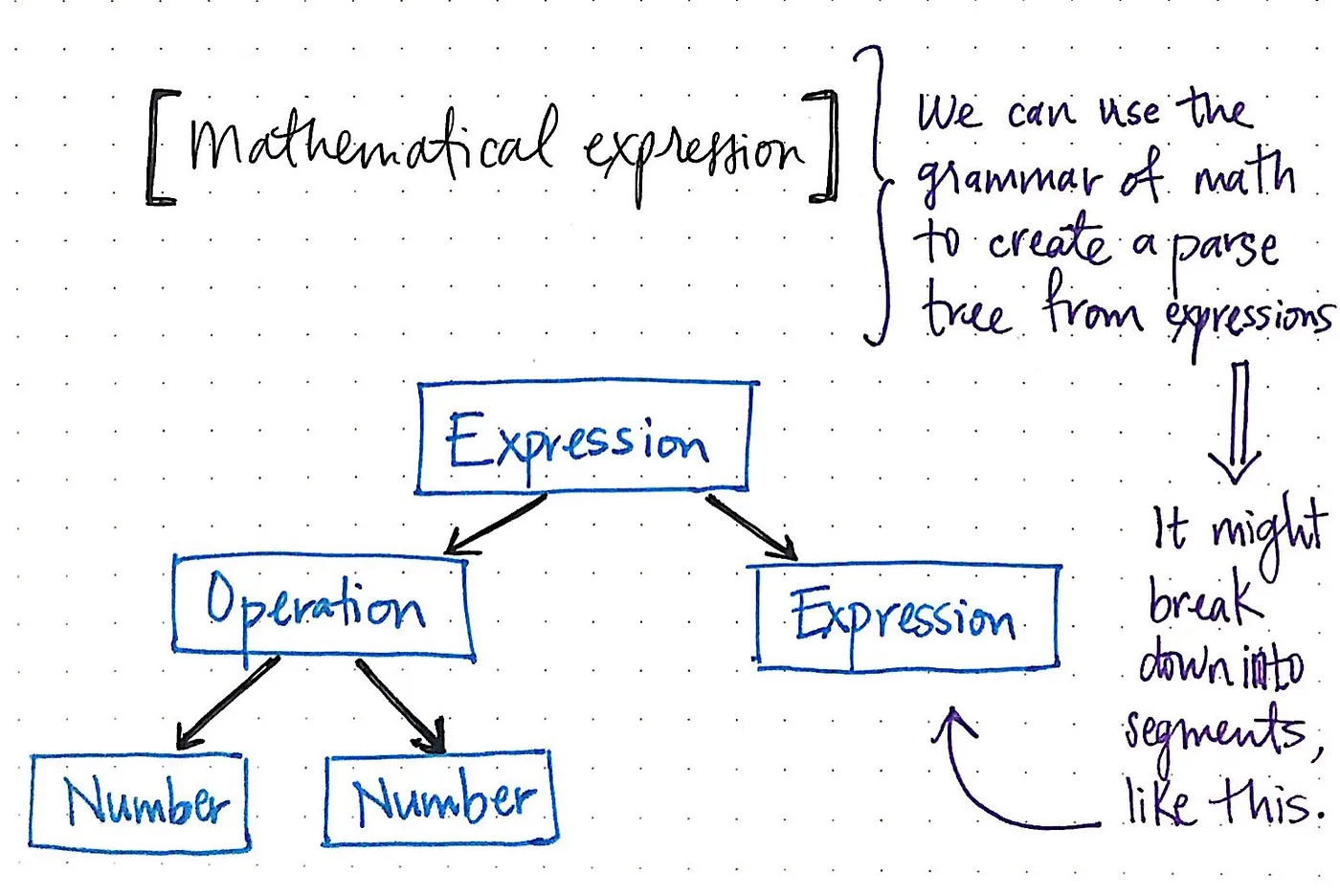
하나의 수학식에도 따라야 할 문법 규칙이 있으며, 두 개의 숫자를 곱한 다음 다른 숫자에 더하는 것과 같은 단순한 표현도 그 자체로 더 간단한 표현으로 나눌 수 있다는 것을 알 수 있습니다.
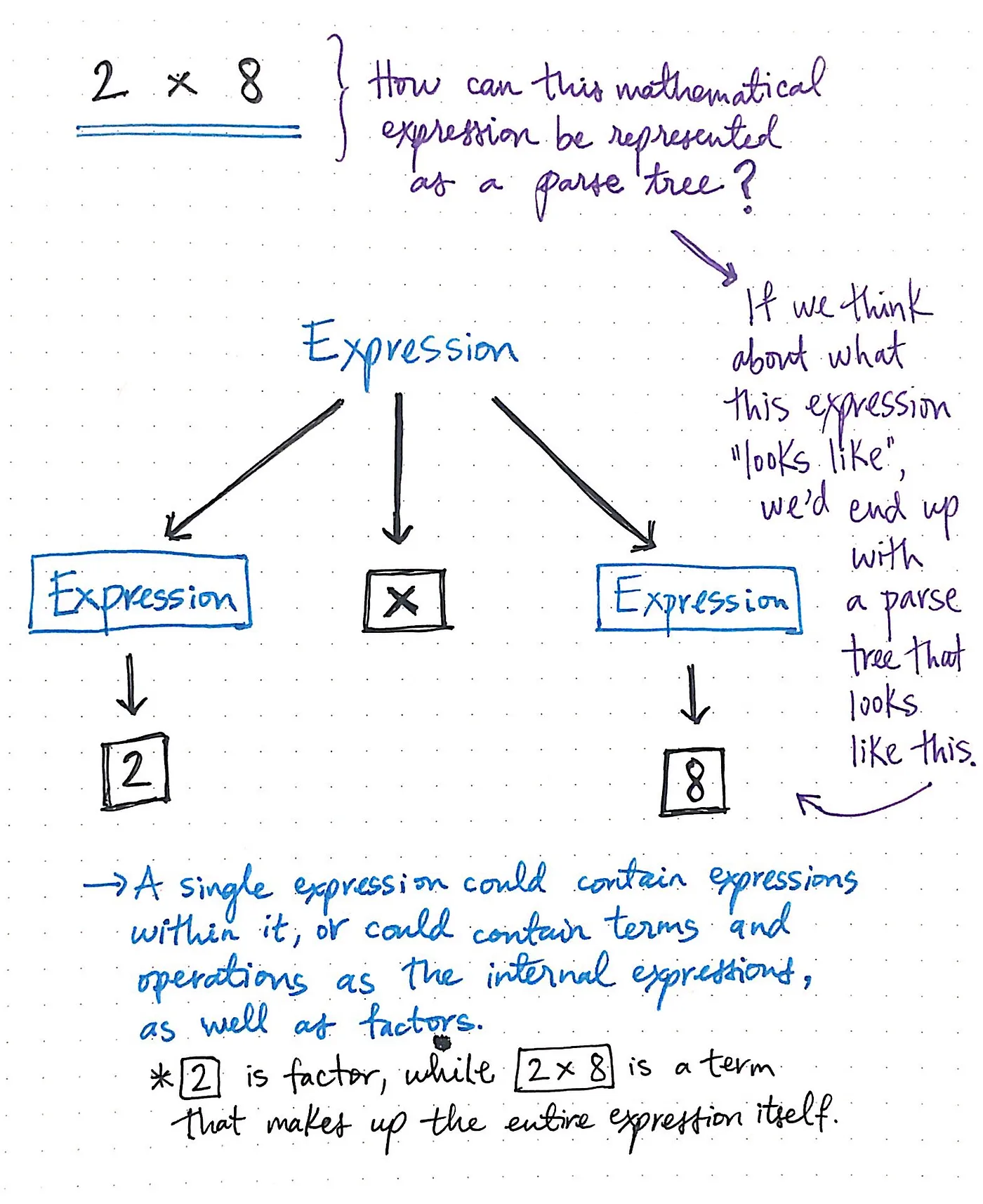
하지만 간단한 계산부터 시작해 보겠습니다. 2 x 8과 같은 표현식에 대해 수학 문법을 사용하여 구문 분석 트리를 만들려면 어떻게 해야 할까요?
이 표현식이 실제로 어떻게 생겼는지 생각해 보면 왼쪽의 표현식, 오른쪽의 표현식, 이 둘을 곱하는 연산 등 세 가지로 구분되는 부분이 있다는 것을 알 수 있습니다.
여기에 표시된 이미지는 표현식 2 x 8을 구문 분석 트리로 도식화한 것입니다. 연산자 x는 더 이상 단순화할 수 없는 표현식의 한 조각이므로 자식 노드가 없다는 것을 알 수 있습니다.
왼쪽과 오른쪽의 표현식은 특정 용어, 즉 2와 8로 단순화할 수 있습니다. 앞서 살펴본 영어 문장의 예와 마찬가지로, 하나의 수학 표현식은 그 안에 내부 표현식뿐만 아니라 2 x 8과 같은 개별 용어 또는 숫자 2와 같은 요소들을 개별 표현식 자체로 포함할 수 있습니다.
하지만 이 구문 분석 트리를 생성한 후에는 어떻게 될까요? 여기서 자식 노드의 계층 구조가 앞의 문장 예제보다 조금 덜 명확하다는 것을 알 수 있습니다. 2와 8이 모두 같은 수준에 있으므로 이를 어떻게 해석할 수 있을까요?
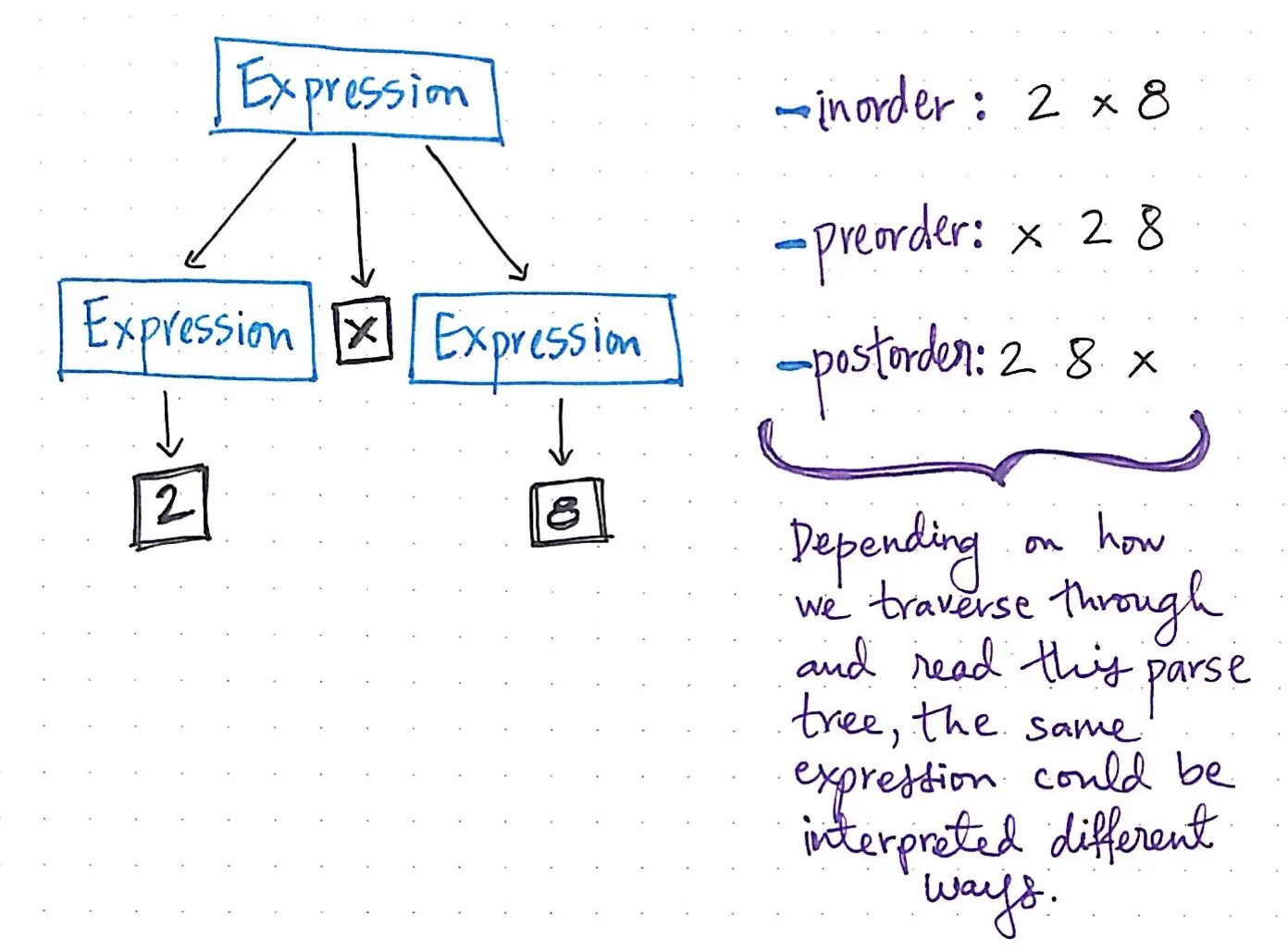
트리를 깊이 우선으로 탐색하는 방법에는 여러 가지가 있다는 것을 이미 알고 있습니다. 이 트리를 탐색하는 방법에 따라 2 x 8이라는 단일 수학 식을 여러 가지 방식으로 해석하고 읽을 수 있습니다. 예를 들어, 순서 순회 탐색을 사용하여 이 트리를 탐색하면 왼쪽 트리, 루트 레벨, 오른쪽 트리를 차례로 읽어서 2 -> x -> 8이 됩니다.
하지만 선순서 탐색을 사용하여 이 트리를 탐색하기로 선택했다면 루트 레벨의 값을 먼저 읽은 다음 왼쪽 하위 트리와 오른쪽 하위 트리를 읽게 되어 x -> 2 -> 8이 됩니다. 그리고 포스트오더 순회 탐색을 사용한다면 왼쪽 하위 트리, 오른쪽 하위 트리를 읽은 다음 마지막으로 루트 레벨을 읽으면 2 -> 8 -> x가 됩니다.
구문 분석 트리는 표현식이 어떻게 생겼는지 보여주며 표현식의 구체적인 구문을 드러내므로, 하나의 구문 분석 트리가 하나의 ‘문장’을 다양한 방식으로 표현할 수 있는 경우가 많습니다. 이러한 이유로 구문 분석 트리는 종종 Concrete Syntax Trees 또는 줄여서 CST라고도 합니다. 이러한 구문 트리를 기계가 해석하거나 “읽으려면” 구문 트리를 구문 분석하는 방법에 대한 엄격한 규칙이 있어야 모든 용어가 올바른 순서와 올바른 위치에 있는 올바른 표현을 얻을 수 있습니다!
하지만 우리가 다루는 대부분의 표현식은 2 x 8보다 더 복잡합니다. 계산기 프로그램의 경우에도 더 복잡한 계산을 수행해야 할 것입니다. 예를 들어 5 + 1 x 12와 같은 식을 풀고자 한다면 어떻게 될까요? 구문 분석 트리는 어떻게 될까요?
구문 분석 트리의 문제점은 때때로 두 개 이상의 트리가 생성될 수 있다는 것입니다.
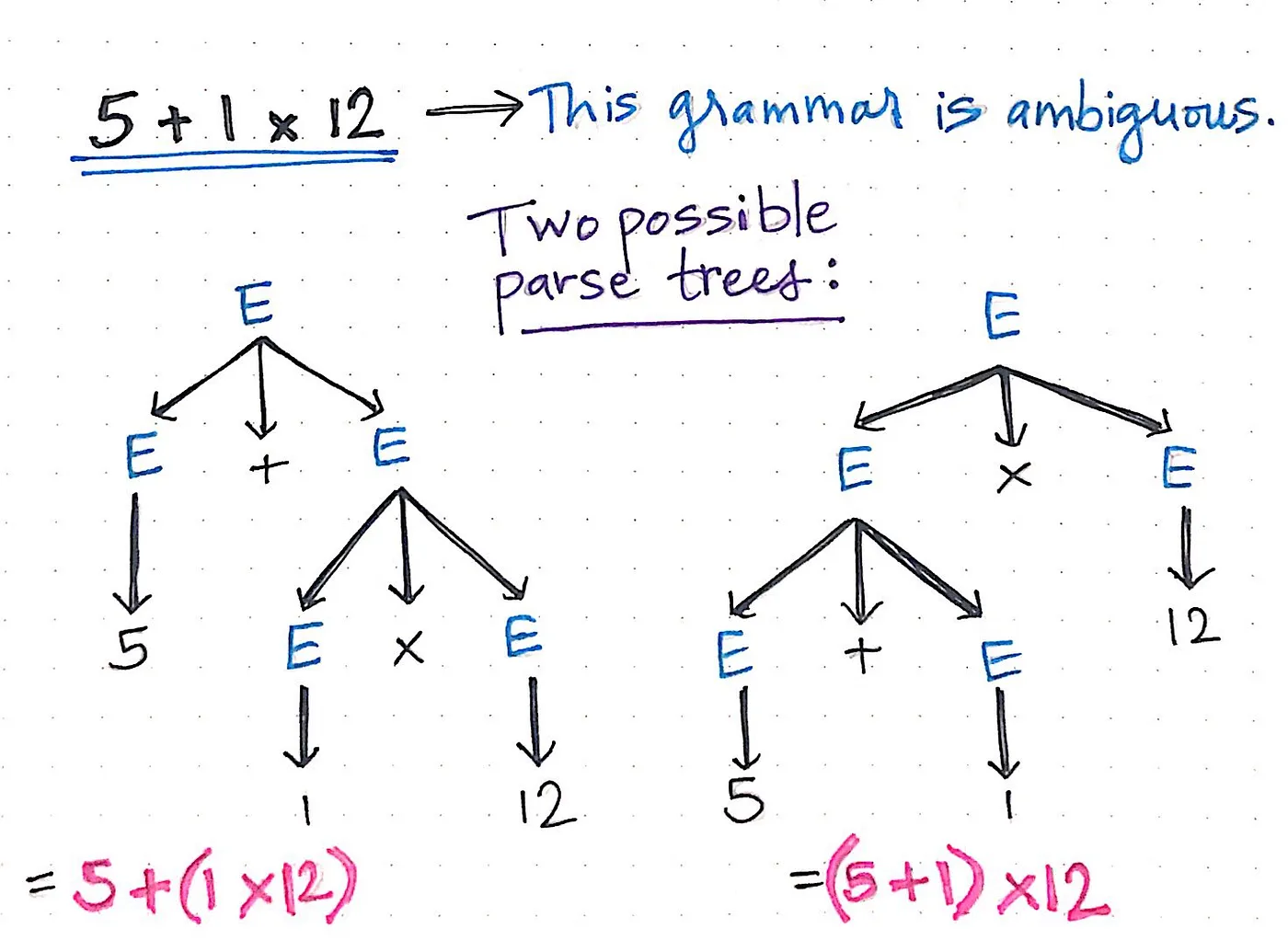
보다 구체적으로, 구문 분석 중인 하나의 표현식에 대해 두 가지 이상의 결과가 있을 수 있습니다. 구문 분석 트리가 가장 낮은 수준에서 먼저 읽힌다고 가정하면, 리프 노드의 계층 구조로 인해 동일한 표현식이 완전히 다른 두 가지 방식으로 해석되어 결과적으로 전혀 다른 두 가지 값이 나올 수 있다는 것을 알 수 있습니다.
예를 들어, 위 그림에서 5 + 1 x 12라는 표현식에 대해 두 가지 가능한 구문 분석 트리가 있습니다. 왼쪽 구문 분석 트리에서 볼 수 있듯이 노드의 계층 구조는 1 x 12 식을 먼저 평가한 다음 덧셈을 계속하도록 되어 있습니다: 5 + (1 x 12). 반면 오른쪽 구문 분석 트리는 노드의 계층 구조가 매우 달라서 덧셈(5 + 1)을 먼저 수행한 다음 트리 위로 이동하여 곱셈을 계속합니다: (5 + 1) x 12.
언어의 모호한 문법은 바로 이러한 상황을 야기합니다. 구문 트리를 구성하는 방법이 불분명하면 구문 트리가 (적어도) 두 가지 이상의 방식으로 구성될 수 있습니다.
하지만 모호한 문법은 컴파일러에게 문제가 될 수 있습니다!

우리 대부분이 학교에서 배운 수학의 규칙에 따르면 곱셈은 항상 덧셈보다 먼저 해야 한다는 것을 본질적으로 알고 있습니다. 즉, 위 예제에서 왼쪽 구문 분석 트리만 수학의 문법에 따라 실제로 올바른 것입니다. 기억하세요: 문법은 영어 문장이든 수학 표현이든 모든 언어의 구문과 규칙을 정의하는 것입니다.
하지만 컴파일러는 도대체 어떻게 이러한 규칙을 본질적으로 알 수 있을까요? 글쎄요, 그럴 수 있는 방법은 전혀 없습니다! 컴파일러에 따라야 할 문법 규칙을 제공하지 않으면 컴파일러는 우리가 작성한 코드를 어떤 방식으로 읽어야 할지 전혀 모를 것입니다. 예를 들어 컴파일러는 두 개의 다른 구문 분석 트리를 생성할 수 있는 수학 식을 작성했다고 해도 두 구문 분석 트리 중 어떤 것을 선택해야 할지 알 수 없으므로 코드를 읽거나 해석하는 방법조차 모르게 됩니다.
모호한 문법은 바로 이러한 이유로 대부분의 프로그래밍 언어에서 일반적으로 피합니다. 실제로 대부분의 구문 분석기와 프로그래밍 언어는 처음부터 의도적으로 모호성 문제를 처리합니다. 프로그래밍 언어에는 일반적으로 _우선순위를_ 강제하는 문법이 있어 일부 연산이나 기호가 다른 연산이나 기호보다 더 높은 가중치/값을 갖도록 강제합니다. 예를 들어 구문 분석 트리를 구성할 때마다 덧셈보다 곱셈에 더 높은 우선 순위를 부여하여 하나의 구문 분석 트리만 구성할 수 있도록 하는 것입니다.
모호성 문제를 해결하는 또 다른 방법은 문법을 해석하는 방식을 강화하는 것입니다. 예를 들어 수학에서 1 + 2 + 3 + 4와 같은 식이 있다면, 우리는 본질적으로 왼쪽부터 더하기 시작하여 오른쪽으로 작업해야 한다는 것을 알고 있습니다. 컴파일러가 자체 코드에서 이 방법을 이해하도록 하려면 왼쪽 연관성을 적용하여 컴파일러가 코드를 파싱할 때 4의 인수를 1의 인자보다 파싱 트리 계층 구조에서 더 아래에 배치하는 파싱 트리를 생성하도록 해야 합니다.
이 두 가지 예는 컴파일러 설계에서 종종 모호성 제거 규칙이라고 불리는데, 특정 구문 규칙을 생성하여 컴파일러가 매우 혼란스러워하는 모호한 문법을 만들지 않도록 하기 때문입니다.
내 애정의 토큰(내 파서를 위한)
모호함이 모든 구문 분석 트리의 악의 근원이라면 명확성이야말로 가장 바람직한 작동 방식입니다. 물론 모호한 상황을 피하기 위해 모호한 규칙을 추가하면 컴퓨터가 코드를 읽을 때 당황할 수 있지만, 실제로는 그보다 훨씬 더 많은 작업을 수행합니다. 오히려 우리가 사용하는 프로그래밍 언어가 더 큰 역할을 합니다!
설명해드리겠습니다. 수학적 표현에 명확성을 더하는 방법 중 하나는 괄호를 사용하는 것이라고 생각하면 됩니다. 사실, 앞서 다루었던 표현식에서도 대부분의 사람들이 괄호를 사용했을 것입니다: 5 + 1 x 12. 우리는 아마도 이 식을 읽고 학교에서 배운 연산 순서를 떠올리며 머릿속으로 다음과 같이 다시 썼을 것입니다: 5 + (1 x 12). 괄호()는 표현식 자체와 그 안에 내재되어 있는 두 가지 표현식을 명확하게 파악하는 데 도움이 됩니다. 이 두 기호는 우리가 알아볼 수 있으며, 구문 분석 트리에 넣으면 더 이상 분해할 수 없으므로 자식 노드가 없습니다.
이를 터미널이라고 하며, 흔히 토큰이라고도 합니다. 토큰은 표현식의 각 부분이 서로 어떻게 연관되어 있는지, 개별 요소 간의 구문 관계를 이해하는 데 도움이 되므로 모든 프로그래밍 언어에서 매우 중요합니다. 프로그래밍에서 흔히 사용되는 토큰으로는 연산 기호(+, -, x, /), 괄호(()), 예약 조건어(if, then, else, end) 등이 있습니다. 일부 토큰은 서로 다른 요소의 관계를 지정할 수 있기 때문에 표현식을 명확히 하는 데 사용됩니다.

그렇다면 구문 분석 트리의 다른 모든 것들은 무엇일까요? 우리 코드에는 if와 + 기호만 있는 것이 아닙니다! 우리는 일반적으로 표현식, 용어 및 잠재적으로 더 세분화할 수 있는 요소인 비단어 집합도 처리해야 합니다. (8 + 1) / 3 식과 같이 그 안에 다른 식을 포함하는 구문/아이디어가 바로 그것입니다.
터미널과 비터미널은 모두 구문 분석 트리에서 나타나는 위치와 특정한 관계가 있습니다. 이름에서 알 수 있듯이 터미널 기호는 항상 구문 분석 트리의 잎으로 끝나는데, 이는 연산자, 괄호 및 예약 조건부뿐만 아니라 모든 잎 노드에 있는 문자열, 숫자 또는 개념을 나타내는 모든 요소 값도 “터미널”이라는 것을 의미합니다. 가능한 가장 작은 조각으로 분해되는 모든 것은 사실상 항상 ‘터미널’이 됩니다.
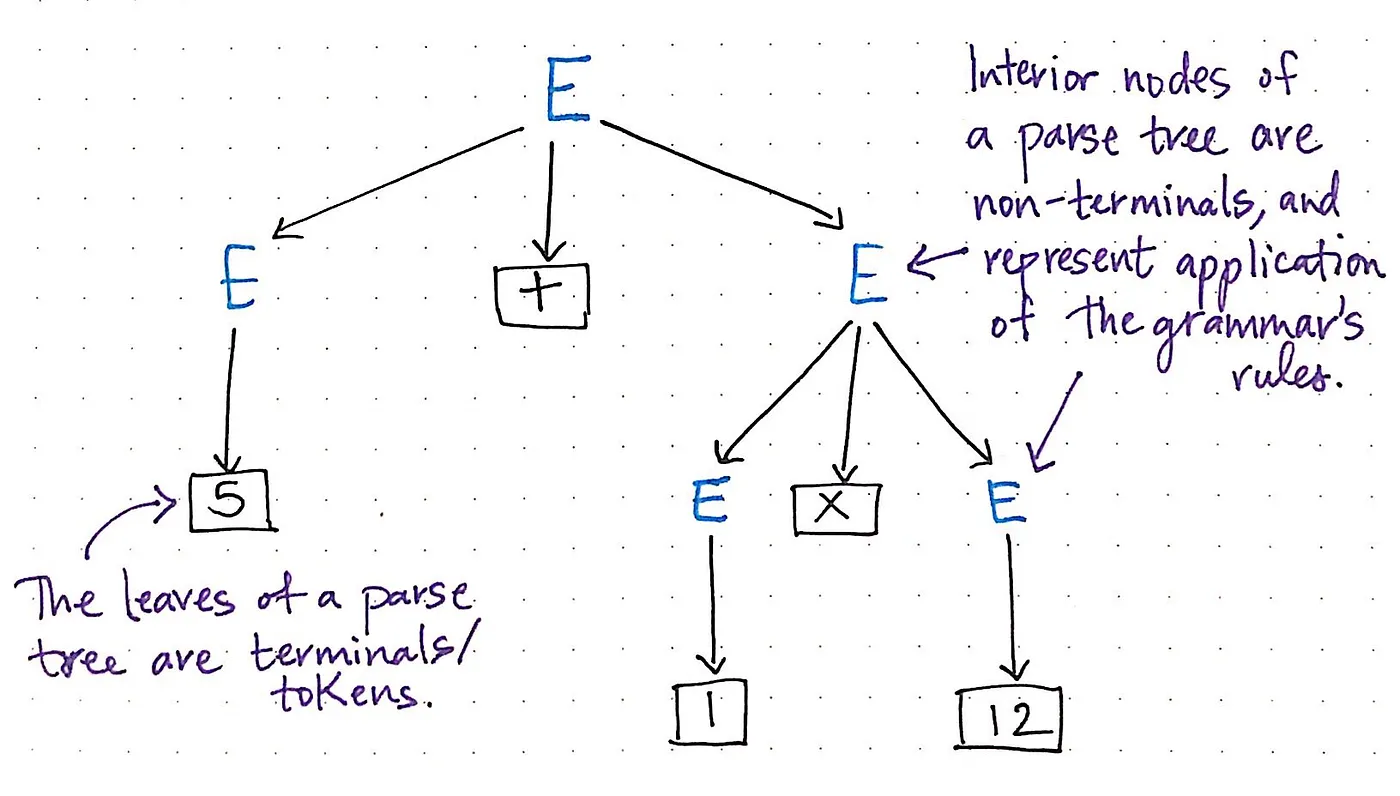
반대로 구문 분석 트리의 내부 노드, 즉 부모 노드인 비-리프 노드(non-leaf node)는 비-터미널(non-terminal) 기호이며 프로그래밍 언어의 문법 규칙을 적용하는 것을 나타내는 노드입니다.
구문 분석 트리는 프로그램과 그 안에 있는 모든 기호, 개념 및 표현을 표현한 것에 불과하다는 사실을 이해하면 훨씬 더 쉽게 이해하고 시각화하며 식별할 수 있습니다.
하지만 구문 분석 트리의 가치는 무엇일까요? 우리는 프로그래머로서 생각하지 않지만, 분명 존재할 이유가 있을 것입니다.

결과적으로 구문 분석 트리를 가장 중요하게 생각하는 것은 우리가 작성하는 모든 코드를 파싱(parsing)하는 프로세스를 처리하는 컴파일러의 일부인 파서(parser)입니다.
구문 분석 프로세스는 실제로 몇 가지 입력을 받아 구문 분석 트리를 만드는 것입니다. 입력은 문자열, 문장, 표현식 또는 전체 프로그램 등 여러 가지가 될 수 있습니다.
어떤 입력을 제공하든 구문 분석기는 해당 입력을 문법 구문으로 구문 분석하고 구문 분석 트리를 구축합니다. 구문 분석기는 컴퓨터와 컴파일 프로세스의 맥락에서 두 가지 주요 역할을 합니다:
- 유효한 토큰 시퀀스가 주어지면 언어의 구문에 따라 해당 구문 분석 트리를 생성할 수 있어야 합니다.
- 유효하지 않은 토큰 시퀀스가 주어지면 구문 오류를 감지하고 코드를 작성한 프로그래머에게 코드의 문제를 알려줄 수 있어야 합니다.
이것이 전부입니다! 정말 간단하게 들릴 수도 있지만, 일부 프로그램이 얼마나 방대하고 복잡할 수 있는지 생각해 보면 구문 분석기가 이 두 가지 쉬운 역할을 실제로 수행하기 위해서는 얼마나 잘 정의되어야 하는지 금방 깨닫게 될 것입니다.
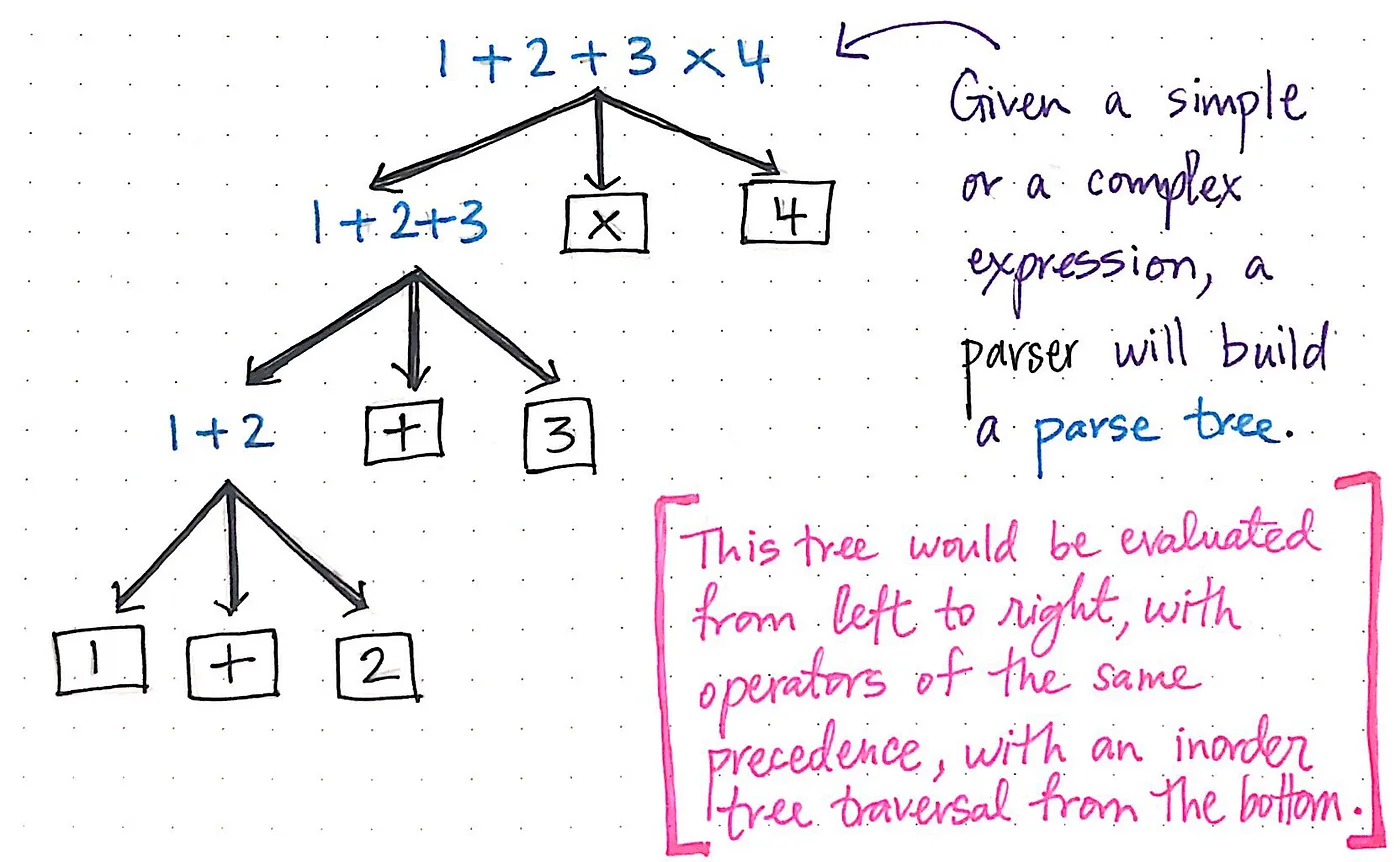
예를 들어, 간단한 구문 분석기라도 1 + 2 + 3 x 4와 같은 식의 구문을 처리하려면 많은 작업을 수행해야 합니다.
-
먼저, 이 표현식에서 구문 분석 트리를 만들어야 합니다. 구문 분석기가 수신하는 입력 문자열에는 연산 간의 연관성이 표시되지 않을 수 있지만 구문 분석기는 이를 표시하는 구문 분석 트리를 만들어야 합니다.
-
하지만 이를 위해서는 언어의 구문과 따라야 할 문법 규칙을 알아야 합니다.
-
(모호함 없이) 단일 구문 분석 트리를 실제로 만들 수 있게 되면 토큰과 비종결 기호를 꺼내 구문 분석 트리의 계층 구조가 정확하도록 정렬할 수 있어야 합니다.
-
마지막으로, 구문 분석기는 이 트리가 평가될 때 동일한 우선순위를 가진 연산자를 사용하여 왼쪽에서 오른쪽으로 평가되도록 해야 합니다.
-
하지만 잠깐만요! 또한 이 트리를 아래에서 순서대로 탐색하는 방법을 사용하여 이 트리를 탐색할 때 단 하나의 구문 오류도 발생하지 않도록 해야 합니다!
-
물론 구문 오류가 발생하면 구문 분석기는 입력을 살펴보고 어디에서 오류가 발생하는지 파악한 다음 프로그래머에게 알려줘야 합니다.
이 작업이 엄청나게 많은 작업처럼 느껴진다면 그 이유는 바로 그 때문입니다. 하지만 이 모든 작업을 수행하는 것에 대해 너무 걱정하지 마세요. 파서가 하는 일이고 대부분은 추상화되어 있기 때문입니다. 다행히도 파서는 컴파일러의 다른 부분으로부터 도움을 받습니다. 다음 주에 더 자세히 설명하겠습니다!
참고자료
다행히도 컴파일러 설계는 거의 모든 컴퓨터 과학 커리큘럼에서 잘 가르치고 있으며, 파서와 구문 분석 트리 등 컴파일러의 여러 부분을 이해하는 데 도움이 되는 자료가 꽤 많이 있습니다. 하지만 대부분의 CS 콘텐츠가 그렇듯이, 특히 개념이나 사용되는 전문 용어에 익숙하지 않은 경우 이해하기 어려운 부분이 많을 수 있습니다. 아래는 더 많은 것을 배우고 싶을 때 구문 분석 트리를 잘 설명해 주는 초보자 친화적인 몇 가지 리소스입니다.
- Parse Tree, Interactive Python
- Grammars, Parsing, Tree Traversals, Professors David Gries & Doug James
- Let’s Build A Simple Interpreter, Part 7, Ruslan Spivak
- A Guide to Parsing: Algorithms and Terminology, Gabriele Tomassetti
- Lecture 2: Abstract and Concrete Syntax, Aarne Ranta
- Compilers and Interpreters, Professor Zhong Shao
- Compiler Basics — The Parser, James Alan Farrell