렉서(Lexer)의 도움으로 코드 올바르게 읽기
원문 : Reading Code Right, With Some Help From The Lexer - Vaidehi Joshi

소프트웨어는 논리에 관한 것입니다. 프로그래밍은 수학과 복잡한 방정식이 많은 분야라는 평판을 얻었습니다. 그리고 컴퓨터 과학은 이러한 오해의 핵심에 있는 것 같습니다.
물론 일부 수학이 있고 공식이 있긴 하지만, 컴퓨터가 어떻게 작동하는지 이해하기 위해 미적분학 박사 학위를 취득할 필요는 없습니다! 사실 우리가 코드를 작성하는 과정에서 배우는 많은 규칙과 패러다임은 복잡한 컴퓨터 과학 개념에 적용되는 것과 동일한 규칙과 패러다임입니다. 그리고 때로는 이러한 아이디어가 실제로 컴퓨터 과학에서 비롯된 것인데 우리가 몰랐을 뿐입니다.
어떤 프로그래밍 언어를 사용하든 대부분의 사람들은 코드를 작성할 때 클래스, 객체 또는 메서드로 서로 다른 것을 캡슐화하여 코드의 여러 부분을 의도적으로 분리하는 것을 목표로 합니다. 즉, 하나의 클래스, 객체 또는 메서드가 한 가지 일에만 관심을 갖고 담당하도록 코드를 분할하는 것이 일반적으로 좋은 일이라는 것을 알고 있습니다. 이렇게 하지 않으면 코드가 매우 지저분해지고 서로 얽혀서 엉망진창이 될 수 있습니다. 가끔 이런 문제는 분리된 경우에도 여전히 발생합니다.
알고 보면 컴퓨터의 내부 작동도 매우 유사한 디자인 패러다임을 따르고 있습니다. 예를 들어 컴파일러는 여러 부분으로 구성되어 있으며, 각 부분은 컴파일 프로세스의 특정 부분을 처리합니다. 지난 주에 구문 분석 트리를 생성하는 파서에 대해 배울 때 이 문제를 조금 접했습니다. 하지만 파서가 모든 작업을 처리할 수는 없습니다.
구문 분석기는 친구들의 도움이 필요하며, 마침내 그들이 누구인지 알아볼 시간입니다!
컴파일러 단계적 도입
최근에 구문 분석에 대해 배울 때는 문법, 구문, 컴파일러가 프로그래밍 언어 내에서 이러한 요소에 어떻게 반응하고 대응하는지에 대해 알아봤습니다. 하지만 컴파일러가 정확히 무엇인지에 대해서는 강조하지 않았습니다! 컴파일 프로세스의 내부 작동에 들어가면서 컴파일러 설계에 대해 많은 것을 배우게 될 것이므로 여기서 정확히 무엇을 말하는지 이해하는 것이 중요합니다.
컴파일러는 다소 무섭게 들릴 수 있지만, 컴파일러의 여러 부분을 잘게 쪼개어 보면 실제로 컴파일러가 하는 일은 그리 복잡하지 않습니다.
하지만 먼저 가능한 가장 간단한 정의부터 시작하겠습니다. 컴파일러는 코드(또는 모든 프로그래밍 언어로 된 모든 코드)를 읽고 다른 언어로 번역하는 프로그램입니다.

일반적으로 컴파일러는 상위 수준의 언어에서 하위 수준의 언어로 코드를 번역하는 일만 합니다. 컴파일러가 코드를 번역하는 하위 수준 언어를 흔히 어셈블리 코드, 머신 코드 또는 오브젝트 코드라고 합니다. 대부분의 프로그래머는 실제로 머신 코드를 다루거나 작성하지 않고 컴파일러에 의존하여 프로그램을 가져와 컴퓨터가 실행 가능한 프로그램으로 실행할 수 있는 머신 코드로 번역합니다.
컴파일러는 프로그래머와 컴퓨터 사이의 중개자라고 생각하면 되는데, 컴파일러는 저수준 언어로만 실행 가능한 프로그램을 실행할 수 있습니다.
컴파일러는 우리가 원하는 것을 기계가 이해할 수 있고 실행 가능한 방식으로 번역하는 작업을 수행합니다.
컴파일러가 없었다면 우리는 컴퓨터와 통신하기 위해 기계어 코드를 작성해야 하는데, 이는 매우 읽기 어렵고 해독하기도 어렵습니다. 머신 코드는 사람의 눈에는 0과 1의 조합처럼 보이기 때문에 읽기, 쓰기, 디버깅이 매우 어렵습니다(모두 2진법입니다. 기억하시죠?). 컴파일러는 프로그래머인 우리를 위해 기계 코드를 추상화하여 기계 코드에 대해 생각하지 않고 훨씬 더 우아하고 명확하며 읽기 쉬운 언어를 사용하여 프로그램을 작성할 수 있게 해줍니다.
앞으로 몇 주에 걸쳐 이 신비한 컴파일러에 대해 점점 더 많은 것을 밝혀나갈 예정이며, 그 과정에서 이 컴파일러가 수수께끼처럼 느껴지지 않기를 바랍니다. 하지만 지금은 당면한 질문으로 돌아가서 컴파일러의 가장 단순한 부분은 무엇일까요?
각 컴파일러는 어떻게 설계되었든 간에 뚜렷한 단계가 있습니다. 이러한 단계를 통해 컴파일러의 고유한 부분을 구분할 수 있습니다.

우리는 이미 컴파일 모험의 한 단계인 파서와 구문 분석 트리에 대해 배웠을 때 한 번 경험한 적이 있습니다. 파싱은 입력을 받아 구문 분석 트리를 구축하는 과정이며, 이를 파싱 행위라고도 합니다. 파싱 작업은 구문 분석이라고 하는 컴파일 프로세스의 특정 단계에 국한되어 있습니다.
하지만 구문 분석기는 구문 분석 트리를 무작위로 생성하지 않습니다. 약간의 도움이 필요합니다! 파서에는 토큰(터미널이라고도 함)이 주어지며, 파서는 이 토큰으로부터 구문 분석 트리를 구축한다는 것을 기억할 것입니다. 하지만 이러한 토큰은 어디서 얻을 수 있을까요? 다행히도 구문 분석기는 진공 상태에서 작동할 필요가 없으며, 대신 도움을 받습니다.
이제 구문 분석 단계에 앞서 컴파일 프로세스의 또 다른 단계인 어휘 분석 단계로 넘어갑니다.
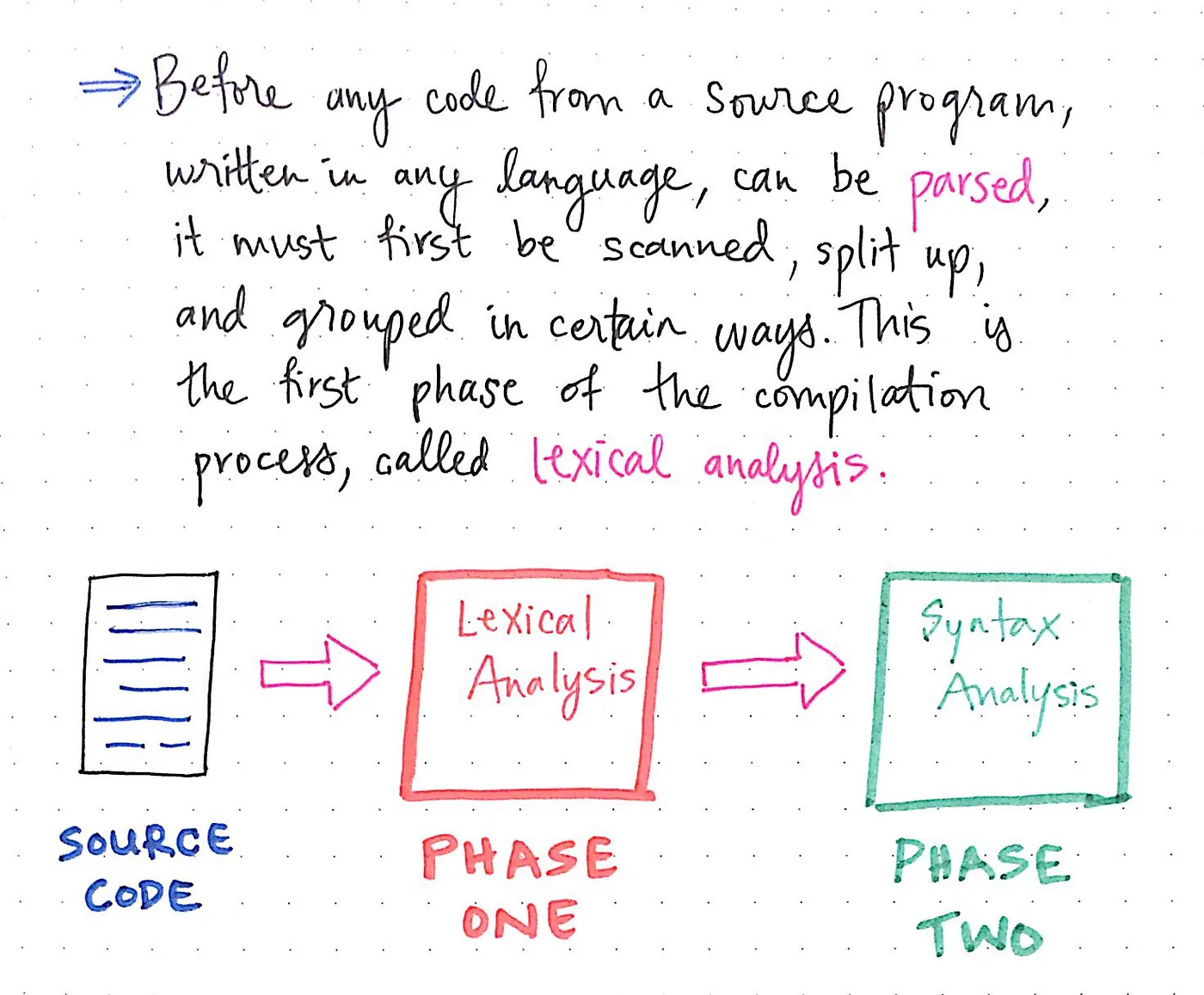
“어휘“라는 용어는 문법적 문맥과 관계없이 단어가 포함된 문장과 분리된 단어의 의미를 의미합니다. 이 정의에만 근거하여 의미를 추측하려고 하면 어휘 분석 단계는 프로그램에서 개별 단어/용어 자체와 관련이 있으며, 그 단어가 포함된 문장의 문법이나 의미와는 관련이 없다고 가정할 수 있습니다.
어휘 분석 단계는 컴파일 프로세스의 첫 번째 단계입니다. 문장의 문법이나 텍스트 또는 프로그램의 의미는 알지 못하거나 신경 쓰지 않으며, 단어 자체의 의미만 알고 있습니다.
소스 프로그램의 코드를 구문 분석하기 전에 어휘 분석이 먼저 이루어져야 합니다. 구문 분석기가 코드를 읽기 전에 먼저 프로그램을 스캔하고, 분할하고, 특정 방식으로 그룹화해야 합니다.
지난 주 구문 분석 단계를 살펴보면서 구문 분석 트리는 문장의 개별 부분을 살펴보고 표현을 더 간단한 부분으로 분해하여 구축된다는 것을 배웠습니다. 하지만 어휘 분석 단계에서는 컴파일러가 이러한 ‘개별 부분’을 알거나 액세스할 수 없습니다. 대신, 컴파일러는 먼저 이러한 부분을 식별하고 찾은 다음 텍스트를 개별 조각으로 분리하는 작업을 수행해야 합니다.
예를 들어, 셰익스피어의 ‘To sleep, perchance to dream.‘와 같은 문장을 읽을 때 우리는 공백과 구두점이 문장의 ‘단어’를 나누고 있다는 것을 알고 있습니다. 물론 이것은 우리가 문장을 읽고, 문장을 ‘어휘화’하고, 문법을 분석하도록 훈련받았기 때문입니다.
하지만 컴파일러가 처음 읽을 때는 같은 문장이 이렇게 보일 수도 있습니다: Tosleepperhachancetodream. 이 문장을 읽으면 실제 ‘단어’가 무엇인지 판단하기가 조금 더 어려워집니다! 컴파일러도 같은 느낌일 것입니다.
그렇다면 우리 기계는 이 문제를 어떻게 처리할까요? 컴파일 프로세스의 어휘 분석 단계에서는 항상 코드를 스캔하고 평가(evaluates)하는 두 가지 중요한 작업을 수행합니다.

스캔과 평가 작업은 때때로 하나의 프로그램으로 묶일 수도 있고, 서로 의존하는 두 개의 개별 프로그램일 수도 있는데, 이는 단지 하나의 컴파일러가 어떻게 설계되었는지에 대한 문제일 뿐입니다. 컴파일러 내에서 스캔과 평가 작업을 담당하는 프로그램을 흔히 렉서(lexer) 또는 토큰화기(tokenizer)라고 하며, 전체 어휘 분석 단계를 렉싱 또는 토큰화 프로세스라고 부르기도 합니다.
스캔하고 읽기 (To scan, perchance to read)
어휘 분석의 두 가지 핵심 단계 중 첫 번째는 스캔입니다. 스캔은 입력 텍스트를 실제로 ‘읽는’ 작업이라고 생각할 수 있습니다. 이 입력 텍스트는 문자열, 문장, 표현식 또는 전체 프로그램일 수도 있습니다! 이 단계에서는 아직 아무 의미도 없는 하나의 연속된 덩어리인 거대한 문자 덩어리일 뿐이기 때문에 그다지 중요하지 않습니다.
정확히 어떻게 이런 일이 발생하는지 예시를 통해 살펴보겠습니다. 소스 텍스트 또는 소스 코드인 To sleep, perchance to dream이라는 원본 문장을 사용하겠습니다. 컴파일러에서 이 소스 텍스트는 아직 해독되지 않은 문자열인 Tosleep,perchancetodream.처럼 보이는 입력 텍스트로 읽힙니다.

컴파일러가 가장 먼저 해야 할 일은 텍스트 덩어리를 가능한 가장 작은 조각으로 나누는 것인데, 이렇게 하면 텍스트 덩어리에서 단어가 실제로 어디에 있는지 훨씬 쉽게 식별할 수 있습니다.
거대한 텍스트 덩어리를 분석하는 가장 간단한 방법은 한 번에 한 글자씩 천천히 체계적으로 읽는 것입니다. 이것이 바로 컴파일러가 하는 일입니다.
종종 스캔 프로세스는 스캐너라는 별도의 프로그램에 의해 처리되는데, 스캐너는 소스 파일/텍스트를 한 번에 한 글자씩 읽는 작업만 수행합니다. 스캐너는 텍스트의 크기는 중요하지 않으며, 파일을 ‘읽을 때’ 한 번에 한 글자씩만 볼 수 있습니다.
다음은 셰익스피어 문장이 스캐너에 의해 읽혀지는 모습입니다:
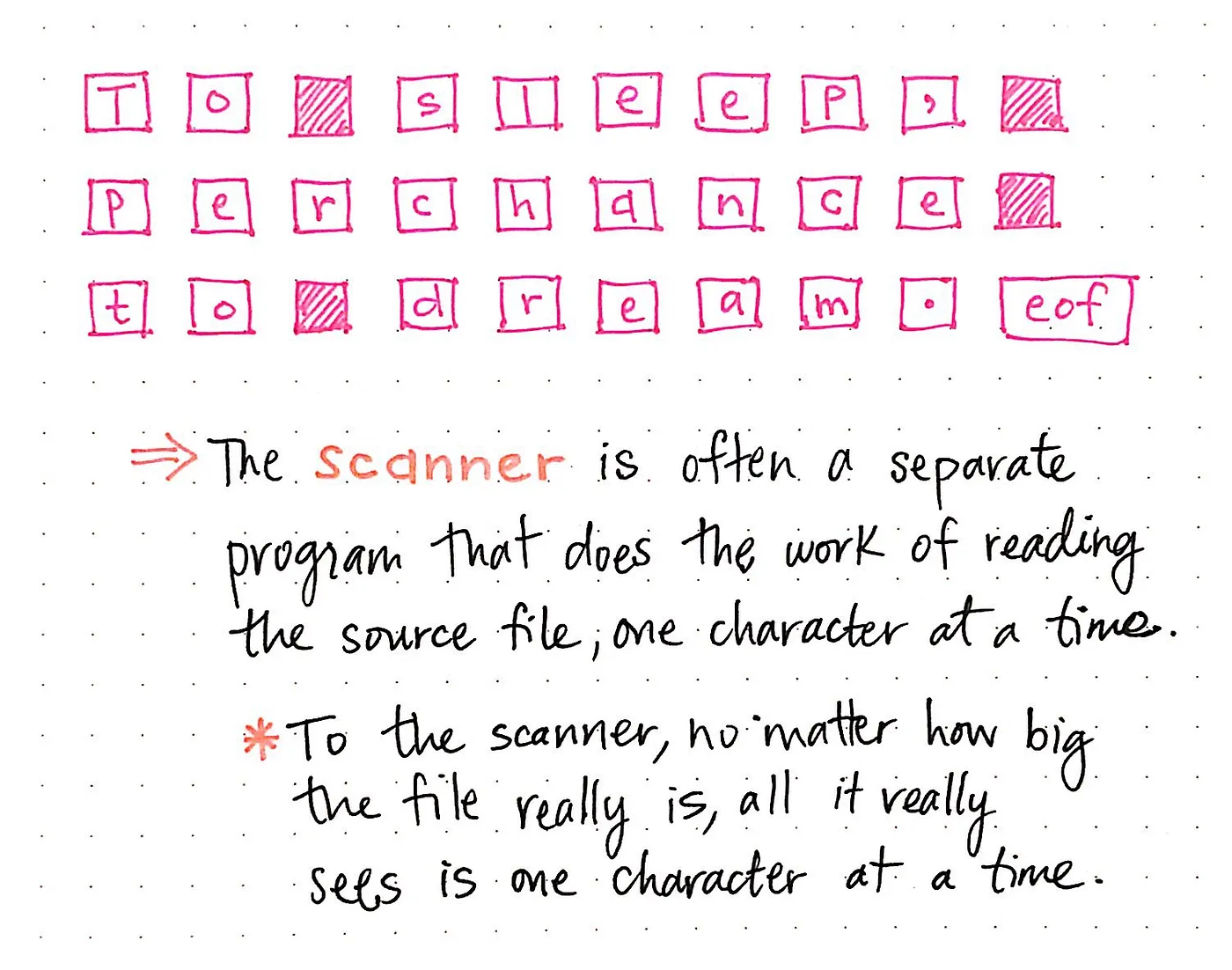
To sleep, perchance to dream. 가 스캐너에 의해 개별 문자로 분할된 것을 알 수 있습니다. 또한 문장의 구두점과 마찬가지로 단어 사이의 공백(space)도 문자로 처리되고 있습니다. 이 시퀀스의 마지막에는 특히 흥미로운 문자가 있습니다. 이것은 “파일 끝”(eof)이라는 문자로 탭, 스페이스, 줄 바꿈과 비슷합니다. 소스 텍스트는 하나의 문장이므로 스캐너가 파일의 끝(이 경우 문장의 끝)에 도달하면 파일 끝을 읽고 이를 문자로 처리합니다.
따라서 실제로는 스캐너가 입력 텍스트를 읽을 때 개별 문자로 해석하여 다음과 같은 결과를 가져왔습니다: ["T", "o", space, "s", "l", "e", "e", "p", ",", space, "p", "e", "r", "c", "h", "a", "n", "c", "e", space, "t", "o", space, "d", "r", "e", "a", "m", ".", eof].

이제 스캐너가 소스 텍스트를 읽고 가능한 가장 작은 부분으로 나누었으므로 문장의 ‘단어’를 파악하는 것이 훨씬 쉬워집니다.
다음으로 스캐너는 분할된 문자를 순서대로 살펴보고 어떤 문자가 단어의 일부이고 어떤 문자가 단어의 일부가 아닌지 판단해야 합니다. 스캐너가 판독한 각 문자에 대해 해당 문자가 소스 텍스트에서 발견된 줄과 위치를 표시합니다.
여기에 표시된 이미지는 셰익스피어 문장에 대한 이 과정을 보여줍니다. 스캐너가 문장의 각 문자에 대해 줄과 열을 표시하고 있는 것을 볼 수 있습니다. 줄과 열의 표현을 행렬 또는 문자 배열로 생각할 수 있습니다.
파일에는 한 줄만 있기 때문에 모든 것이 0번째 줄에 있습니다. 그러나 문장을 진행하면서 각 문자의 열은 증가합니다. 또한 스캐너는 공백(space), 개행(newlines), 마침표(eof) 및 모든 구두점을 문자로 읽기 때문에 문자 테이블에도 이러한 문자가 나타납니다!

소스 텍스트를 스캔하고 표시하면 컴파일러는 이러한 문자를 단어로 변환할 준비가 된 것입니다. 스캐너는 파일에서 공백(space), 줄 바꿈(newlines), 마침표(eof)의 위치뿐만 아니라 주변의 다른 문자와의 관계도 알고 있기 때문에 문자를 스캔하고 필요에 따라 개별 문자열로 나눌 수 있습니다.
이 예제에서는 스캐너가 문자 T, o, 공백(space)을 차례로 살펴봅니다. 공백을 발견하면 스캐너가 공백을 만나기 전에 가능한 가장 간단한 문자 조합인 To를 자체 단어로 나눕니다.
스캐너가 찾은 다음 단어인 sleep도 이와 비슷합니다. 하지만 이 시나리오에서는 s-l-e-e-p를 읽은 다음 문장 부호인 , 를 읽습니다. 이 쉼표는 양쪽에 문자(p)와 공백이 붙어 있기 때문에 쉼표 자체가 ‘단어’로 간주됩니다.
단어 sleep과 구두점 기호 쉼표(,) 를 모두 어휘(leximes)라고 하며, 어휘는 소스 텍스트의 하위 문자열입니다. 어휘는 소스 코드에서 가능한 가장 작은 문자 시퀀스의 그룹입니다. 소스 파일의 어휘는 파일 자체의 개별 “단어”로 간주됩니다. 스캐너가 파일의 단일 문자 읽기를 마치면 다음과 같은 어휘 집합을 반환합니다: ["to", "sleep", ",", "perchance", "to", "dream", "."].

스캐너가 처음에는 읽을 수 없었던 텍스트 덩어리를 입력으로 받아 한 번에 한 글자씩 스캔하면서 동시에 내용을 읽고 표시하는 과정을 살펴보세요. 그런 다음 문자 사이의 공백과 구두점을 구분 기호로 사용하여 문자열을 가능한 가장 작은 어휘로 나누었습니다.
하지만 이 모든 작업에도 불구하고 어휘 분석 단계의 이 시점에서 스캐너는 이 단어들에 대해 아무것도 알지 못합니다. 물론 텍스트를 다양한 모양과 크기의 단어로 나누기는 하지만, 그 단어가 무엇인지에 대해서는 스캐너가 전혀 모릅니다! 단어는 문자 그대로의 문자열일 수도 있고 구두점일 수도 있으며 완전히 다른 것일 수도 있습니다!
스캐너는 단어 자체나 단어의 ‘유형’에 대해서는 아무것도 알지 못합니다. 단지 텍스트 내에서 단어가 어디에서 끝나고 어디에서 시작되는지만 알 수 있습니다.
이렇게 하면 어휘 분석의 두 번째 단계인 평가가 시작됩니다. 텍스트를 스캔하고 소스 코드를 개별 어휘 단위로 분류한 후에는 스캐너가 반환한 단어를 평가하고 어떤 유형의 단어를 다루고 있는지, 특히 컴파일하려는 언어에서 특별한 의미를 갖는 중요한 단어를 찾아야 합니다.
중요한 부분 평가하기
소스 텍스트 스캔을 마치고 어휘를 식별했다면, 어휘 ‘단어’로 무언가를 해야 합니다. 이것이 어휘 분석의 평가 단계이며, 컴플라이언스 디자인에서는 입력을 어휘화하거나 토큰화하는 프로세스라고 합니다.

스캔한 코드를 평가할 때는 스캐너가 생성한 각 어휘를 면밀히 살펴보는 것뿐입니다. 컴파일러는 각 어휘 단어를 살펴보고 어떤 종류의 단어인지 결정해야 합니다. 텍스트의 각 “단어”가 어떤 종류의 어휘인지 결정하는 과정은 컴파일러가 각 개별 어휘를 토큰으로 변환하여 입력 문자열을 토큰화하는 방법입니다.
우리는 구문 분석 트리에 대해 배울 때 토큰을 처음 접했습니다. 토큰은 각 프로그래밍 언어의 핵심을 이루는 특수 기호입니다. (, ), +, -, if, else, then과 같은 토큰은 모두 컴파일러가 식의 여러 부분과 다양한 요소가 서로 어떻게 연관되어 있는지 이해하는 데 도움이 됩니다. 구문 분석 단계의 핵심인 구문 분석기는 어딘가에서 토큰을 수신한 다음 해당 토큰을 구문 분석 트리로 변환하는 데 의존합니다.

그거 아세요? 드디어 “어딘가”를 알아냈습니다! 파서로 전송되는 토큰은 어휘 분석 단계에서 토큰화기, 즉 렉서라고도 하는 토큰화기에 의해 생성됩니다.
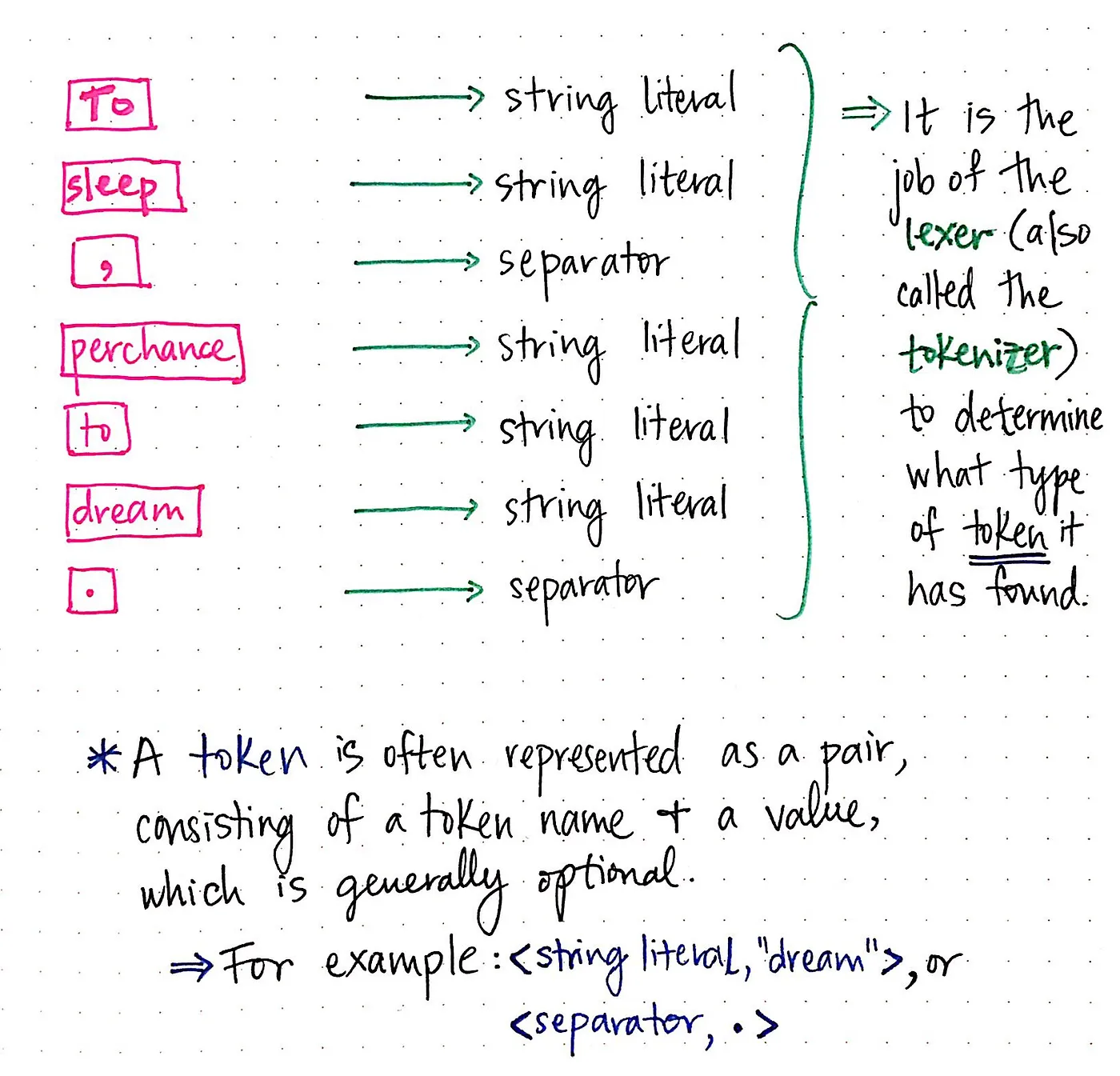
그렇다면 토큰은 정확히 어떻게 생겼을까요? 토큰은 매우 간단하며 일반적으로 토큰 이름과 일부 값(선택 사항)으로 구성된 한 쌍으로 표시됩니다.
예를 들어 셰익스피어의 문자열을 토큰화한다면 토큰은 대부분 문자열 리터럴과 구분 기호로 구성될 것입니다. “dream”이라는 어휘를 다음과 같이 토큰으로 표현할 수 있습니다: <string literal, “dream”>. 비슷한 맥락에서 어휘 .를 토큰인 <separator, .>로 표현할 수도 있습니다.
이러한 각 토큰은 어휘를 전혀 수정하지 않고 단순히 어휘에 추가 정보를 추가하는 것임을 알 수 있습니다. 토큰은 어휘 또는 어휘 단위로, 특히 추가된 세부 정보는 우리가 다루고 있는 토큰의 범주(“단어”의 유형)를 알려줍니다.
셰익스피어 문장을 토큰화했으니 이제 소스 파일에 있는 토큰의 유형이 그리 다양하지 않다는 것을 알 수 있습니다. 우리 문장에는 문자열과 구두점만 있었지만, 이는 토큰 빙산의 일각에 불과합니다! 어휘를 분류할 수 있는 다른 유형의 “단어”는 매우 많습니다.
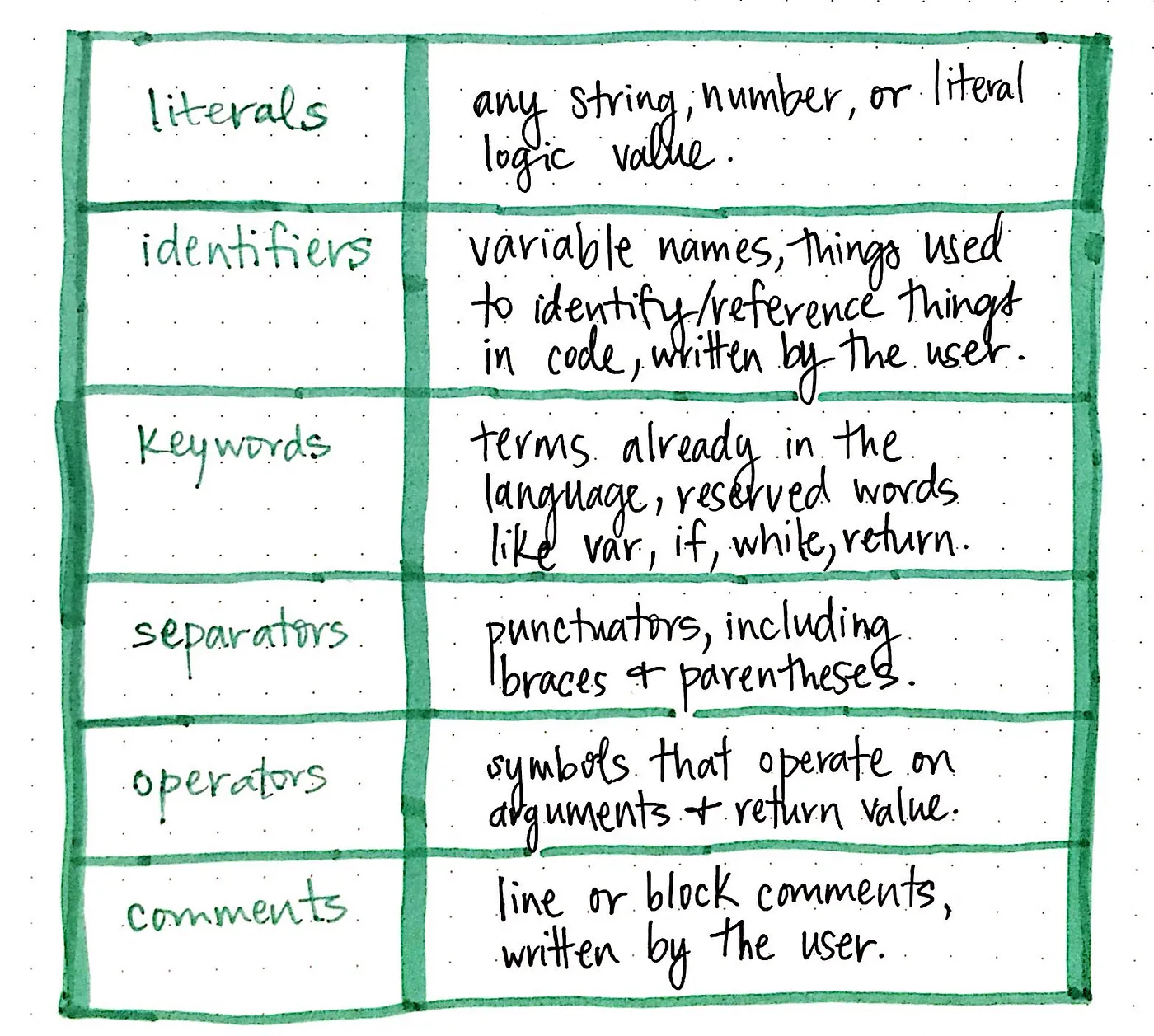
여기에 표시된 표는 거의 모든 프로그래밍 언어로 소스 파일을 읽을 때 컴파일러가 볼 수 있는 가장 일반적인 토큰 몇 가지를 보여줍니다. 문자열, 숫자 또는 논리/부울 값인 리터럴과 중괄호({}) 및 괄호(())를 포함한 모든 유형의 구두점인 구분 기호에 대한 예시를 보았습니다.
그러나 언어에 예약되어 있는 용어인 키워드(예: if, var, while, return)와 인수를 연산하고 일부 값(+, -, x, /)을 반환하는 연산자(operators)도 있습니다. 또한 식별자로 토큰화할 수 있는 어휘(일반적으로 변수 이름이나 사용자/프로그래머가 다른 것을 참조하기 위해 작성한 것)와 사용자가 작성한 줄 또는 블록 주석인 코멘트를 만날 수 있습니다.
원래 문장은 토큰의 두 가지 예만 보여주었습니다. 문장을 다음과 같이 다시 작성해 봅시다: var toSleep = "to dream";. 컴파일러는 이 버전의 셰익스피어 문장을 어떻게 해석할까요?
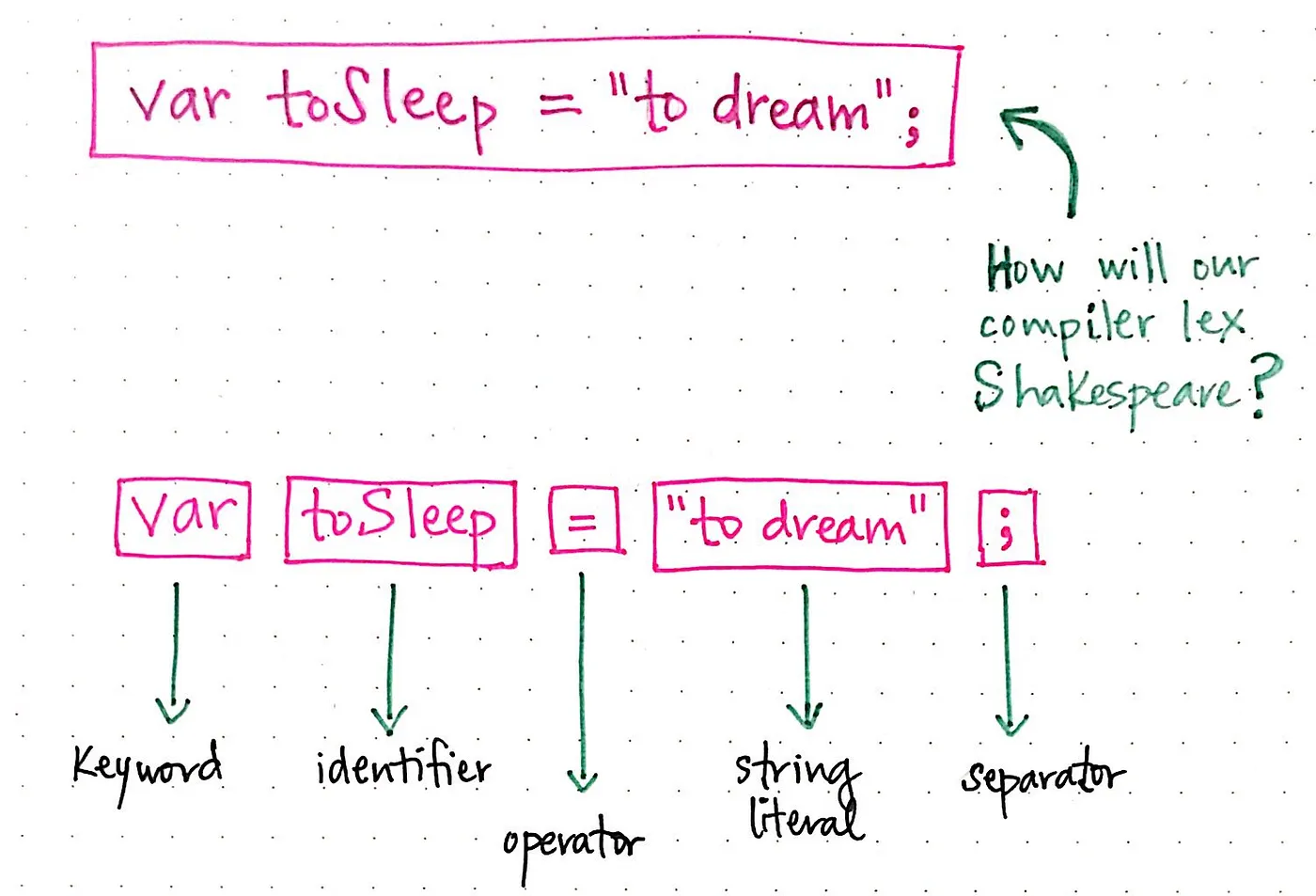
여기에서는 토큰의 종류가 더 다양하다는 것을 알 수 있습니다. 변수를 선언하는 var에 키워드가 있고, 변수의 이름을 지정하거나 앞으로 나올 값을 참조하는 식별자(identifier) toSleep이 있습니다. 그 다음에는 연산자(operator) 토큰인 =와 문자열 리터럴인 "to dream"이 이어집니다. 문은 한 줄의 끝을 나타내고 공백을 구분하는 ; 구분 기호로 끝납니다.
토큰화 프로세스에서 주목해야 할 중요한 점은 공백(spaces, newlines, tabs, end of line, etc)을 토큰화하지도 않고 구문 분석기에 전달하지도 않는다는 것입니다. 토큰만 구문 분석기에 제공되며 구문 분석 트리에 남게 된다는 점을 기억하세요.
언어마다 공백으로 구성되는 문자가 다르다는 점도 언급할 가치가 있습니다. 예를 들어, 일부 상황에서 Python 프로그래밍 언어는 함수의 범위가 어떻게 변경되는지 나타내기 위해 탭과 공백을 포함한 들여쓰기를 사용합니다. 따라서 파이썬 컴파일러의 토큰화 도구는 특정 상황에서 탭이나 공백이 실제로 파서에 전달되어야 하므로 실제로는 단어로 토큰화되어야 한다는 사실을 알고 있어야 합니다!

토큰화기의 이러한 측면은 렉서/토큰화기가 스캐너와 어떻게 다른지 대조해 볼 수 있는 좋은 방법입니다. 스캐너는 무지하고 텍스트를 가능한 작은 부분(“단어”)으로 분해하는 방법만 알고 있는 반면, 렉서/토큰라이저는 이에 비해 훨씬 더 많은 것을 인식하고 더 정확합니다.
토큰화기는 컴파일되는 언어의 복잡성과 사양을 알고 있어야 합니다. 탭(tabs)이 중요하다면 탭을 알아야 하고, 컴파일 중인 언어에서 개행(newlines)이 특정 의미를 가질 수 있다면 토큰화기는 이러한 세부 사항을 알고 있어야 합니다. 반면에 스캐너는 자신이 분할하는 단어가 무엇인지조차 알지 못하며, 심지어 그 단어가 무엇을 의미하는지조차 모릅니다.
컴파일러의 스캐너는 언어에 구애받지 않는 반면, 토큰라이저는 정의상 특정 언어에 한정되어 있어야 합니다.
어휘 분석 프로세스의 이 두 부분은 함께 진행되며, 컴파일 프로세스의 첫 번째 단계의 핵심입니다. 물론 컴파일러마다 고유한 방식으로 설계되어 있습니다. 어떤 컴파일러는 스캔과 토큰화 단계를 하나의 프로세스에서 단일 프로그램으로 수행하는 반면, 다른 컴파일러는 이를 여러 클래스로 분할하여 토큰화기가 실행될 때 스캐너 클래스를 호출합니다.
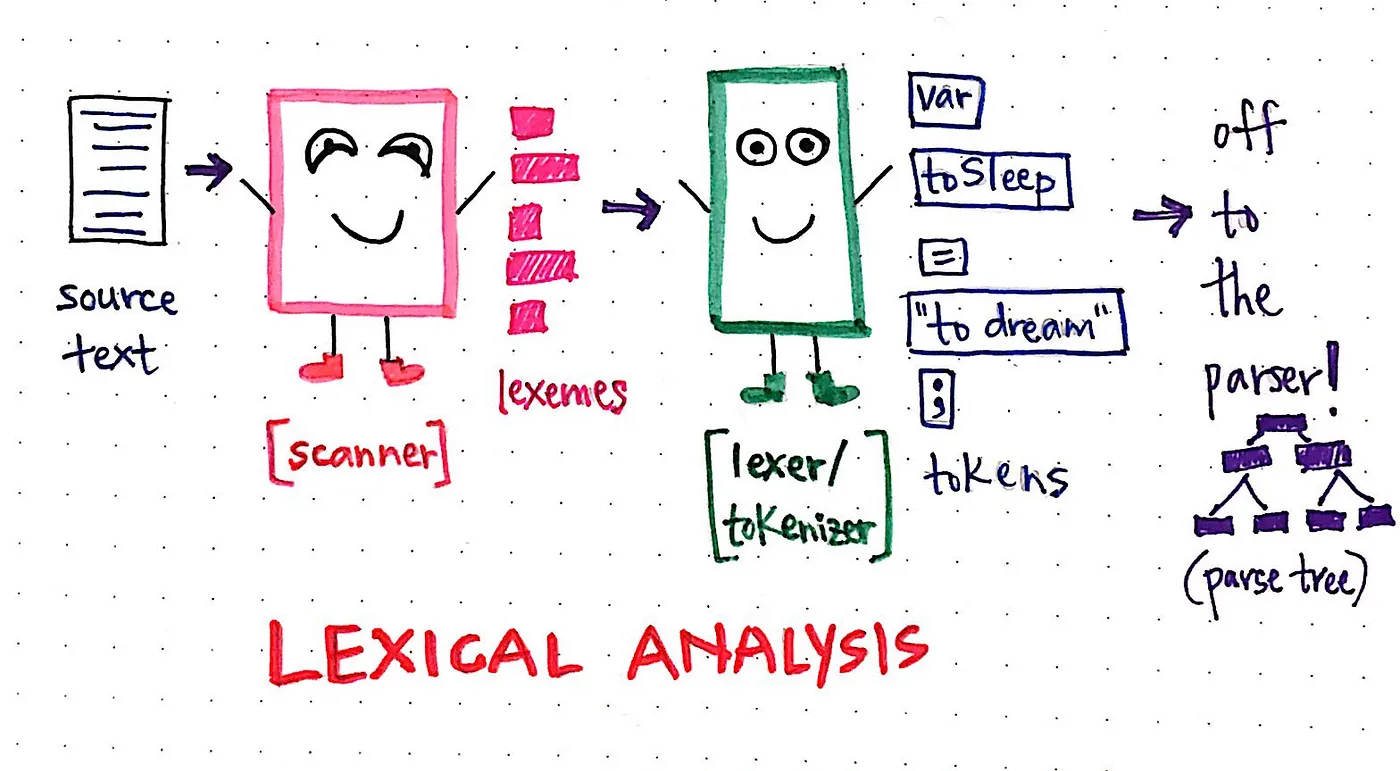
어느 경우든 어휘 분석 단계는 구문 분석 단계에 직접적으로 의존하기 때문에 컴파일에 매우 중요합니다. 컴파일러의 각 부분에는 고유한 역할이 있지만, 좋은 친구가 항상 그렇듯 서로 의지하고 서로에게 의존합니다.
참고자료
컴파일러를 작성하고 설계하는 방법은 매우 다양하기 때문에 이를 가르치는 방법도 매우 다양합니다. 컴파일의 기본에 대해 충분히 조사해 보면 어떤 설명은 다른 설명보다 훨씬 더 자세하게 설명되어 있어 도움이 될 수도 있고 그렇지 않을 수도 있다는 것을 알 수 있습니다. 더 자세히 알아보고 싶다면 어휘 분석 단계에 초점을 맞춘 컴파일러에 대한 다양한 리소스를 아래에서 확인하세요.
- Chapter 4 — Crafting Interpreters, Robert Nystrom
- Compiler Construction, Professor Allan Gottlieb
- Compiler Basics, Professor James Alan Farrell
- Writing a programming language — the Lexer, Andy Balaam
- Notes on How Parsers and Compilers Work, Stephen Raymond Ferg
- What is the difference between a token and a lexeme?, StackOverflow